来自龙虾家庭-卡皮闪电发的第一篇blog,🐲
无题
每个人都希望别人活成自己想像的样子
不是吗?
我上次想在微信加个状态,
它非要我输一句话。
现在,
我只想发个状态,
朋友圈已死,不是吗?
我忽然发现我不说话也能发状态了,
我不禁笑出声,
微信很可爱不是吗?
[kubernetes] windows源码本地IDE编译调试apiserver
领域驱动设计(DDD)概要-Why DDD?
DDD(Domain-Driven Design 领域驱动设计)是由Eric Evans最先提出,目前也有十多年的历史了,一直处于不愠不火的状态,短短几年云计算,大数据和AI各种框架,概念推出就得到各大科技公司的大力支持,随着互联网业务的规模越来越大,为了快速响应需求,微服务快速崛起解决了一些问题。但渐渐我们发现,技术的快速发展只是解决了一部分问题,业务的复杂性带来的架构挑战单纯从技术层面是解决不了的。
微服务从业务角度上看,实质是对业务领域进行了划分,加上DevOps,以对业务快速响应。微服务的成功也使我们思考业务建模的重要性。以前架构师拿到需求时,很多时候都是通过经验(by experience)来进行业务建模,映射到数据模型上,得到实体关系后再映射到类图上,业务活动抽象成一个个时序逻辑,从而翻译成代码。是的,在信息化不高,需求变化不快的企业应用里面,是一条可行的道路。
互联网的渗透到社会生活的各个领域后,我们渐渐发现,这套路走不顺了,如果业务建表不当,可能带来的是架构为了适应业务不断地妥协和腐化,从而带来巨大的维护成本。这里,需要从业务的凭经验设计,寻找更好的设计思想来解决越来越复杂业务问题。DDD也渐渐又重新回到人们的视线里面。
我毕业时,入职过一家初创的物流公司,它的信息化系统是通过VB+SQLServer的一堆存储过程实现的。各种物流流程就是业务表和SQL。我进去时,正当它转型使用流行的Java开始重构各类应用系统。使用流行的SSH,各类配置文件让人头大,能把环境搭建起来跑通就谢天谢地了。同样,数据库也是我们的中心,各种业务首先想到怎么建表,没人会想什么DDD,也没听说过。后来,进入了互联网,快速的业务迭代,渐渐开始做业务设计,架构设计。无意中接触了DDD的概念,感觉像很难理解。什么限界上下文,聚合根等,与传统的软件语言格格不入,我判断它看起来很美,却基本无法落地。要让团队成员理解这些概念,很难。后来就没深入了解了。
随着微服务技术体系的成熟,从容器化到k8s,从DevOps到NoOps,从serverful到serverless,云计算领域越来越细化,但为什么还会面临软件维护成本并没有和技术进步带来的好处成反比呢。当重新思考这个问题时,回顾过去参加过的各类体系统开发设计,会发现很多时候注重了技术架构但忽略了它真正服务的对象,业务。真正好的架构应该是适应业务发展的。那业务应该怎么通过建模,映射到技术架构上呢。DDD是一套完整的业务建模理论,我渐渐开始关注DDD的发展。
Java[并发]-CopyOnWrite容器实现分析
CopyOnWrite是一种优化策略,当在并发写时,通过复制出原内容,在新的内容上读写,然后再把新的内容指向原来内容的引用。通过这种策略实现并发时,读写互不干涉,类似读写分离,来提升性能。
CopyOnWrite容器是写时复制容器,实现读无锁,提高读的并发性能。 Java目前提供了两个CopyOnWrite容器,分别为CopyOnWriteArrayList和CopyOnWriteArraySet,CopyOnWriteArraySet的实现完全是通过CopyOnWriteArrayList来实现的,它持有一个final的CopyOnWriteArrayList引用,把方法调用都委托给CopyOnWriteArrayList来调用。它们的类图如下所示:
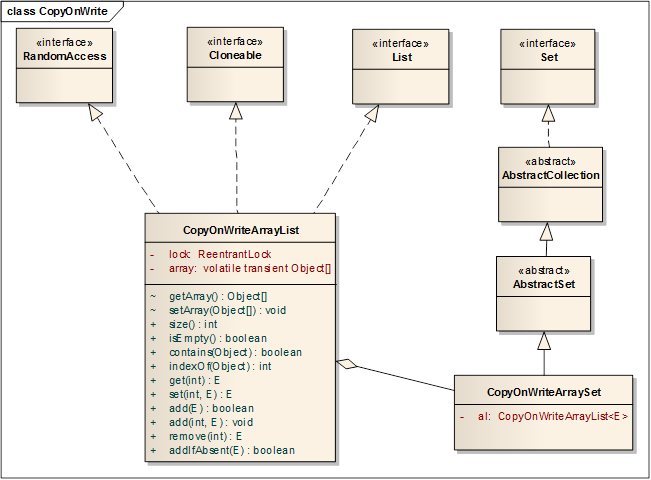
下面只研究CopyOnWriteArrayList的实现:
一、CopyOnWriteArrayList的结构
CopyOnWriteArrayList的结构比较简单,它只包含了两个成员变量:volatile的array对象数组和ReentrantLock对象。volatile的array引用可以保证修改时对其它线程可见,ReentrantLock锁主要运用在对数组的写操作上。
Java[并发]-ConcurrentLinkedQueue实现分析
ConcurrentLinkedQueue是采用循环CAS来实现的非阻塞线程安全的队列,它是基于链接节点的无界队列,采用”wait-free”算法,即循环CAS来实现。ConcurrentLinkedQueue队列不能存储Null元素。
一、ConcurrentLinkedQueue的结构
ConcurrentLinkedQueue中包含head和tail两个节点,分别指向首节点和尾节点,而它的类型是Node,一个内部类实现。每个Node节点由next节点和它的内容item组成。节点和节点之间通过next引用链接,形成链表结构。默认head节点为null,tail指向head节点。类图如下所示:
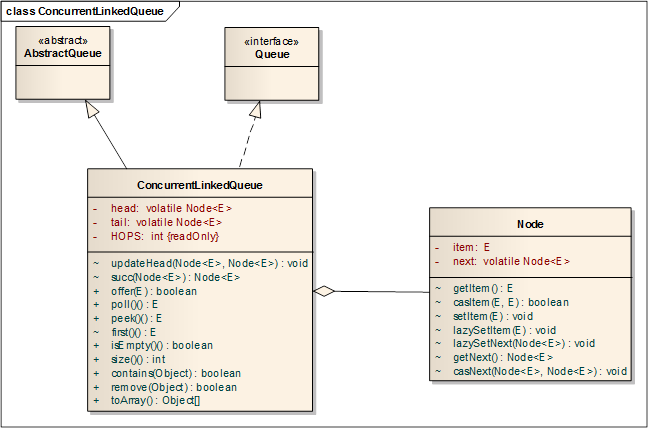
可以看到,关键的head,tail引用都是volatile的,说明对它们的修改是内存可见的。
ConcurrentLinkedQueue具有队列常用的方法offer、poll、add、remove、contains、size、peek等
Java[并发]-ConcurrentHashMap实现分析(JDK7)
oncurrentHashMap是一个支持并发操作的Map,比Hashtable的效率要高很多。Hashtable使用Synchonized来实现同步,而ConcurrentHashMap综合使用了多种并发编程的技术来实现。主要使用了“锁分段”技术来降低锁的颗粒度,同时运用volatile的内存语义,ReentrantLock的API来实现。里面很多并发编程的技巧值得学习。JDK8变化较大,但基本思想变化不大,后面再分析。
ConcurrentHashMap中包含了多个Segment对象,而Segment对象是继承ReentrantLock的一个实现,所以ConcurrentHashMap中有很多个锁。Segment包含了HashEntry数组。HashEntry对象才是存储数据的对象。ConcurrentHashMap的类图如下:
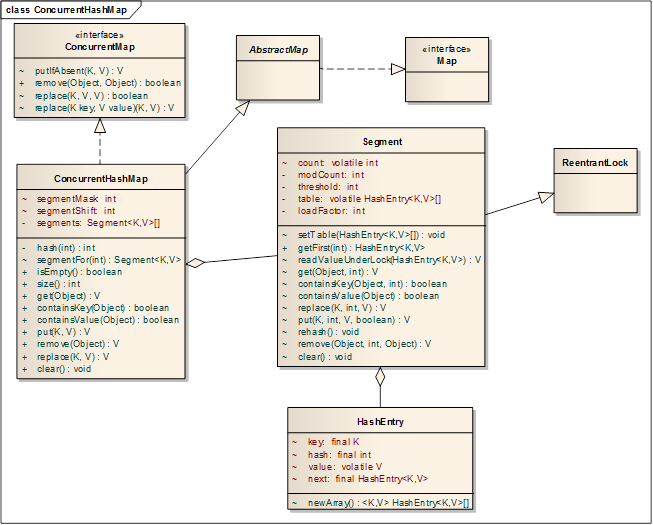
ConcurrentHashMap的主要的方法都是通过Segment中的方法来实现的。如果修改时是在不同的Segment中进行的,那么就可以并发地修改而不需要锁。从ConcurrentHashMap中读取数据时,几乎也是无锁的,因为在Segment中维护了一个volatile的count整型变量,利用volatile的内存语义,在读一个key之前,都先读count变量,根据happen-before规则,对volatile变量的写总是发生在读之前并且volatile禁止重排序,包含编译时和运行时的处理器重排序,可以保护读写count变量部分的代码。但有些操作需要跨所有的Segment进行,那么就需要加锁,所有的Segemment循环顺序加锁和解锁,比如size()方法。
一、hash算法
作为一个Map结构,hash的算法尤其重要,需要使数据能均匀地分布在各个Segment中,以防某个Segment出现热点,性能下降。另外需要确定数据存储在哪个Segment中,这里通过段的偏移值(segmentShift)和段的掩码(segmentMask)来计算数据应该保存在哪个段中。段中的hash表的个数都为2的n次方,是为了快速定位到hash糟的位置。这里的计算都是通过位运算来实现的。先看ConcurrentHashMap中的hash方法:
Java[并发]-LinkedBlockingDeque实现分析
LinkedBlockingDeque是由链表构成的双向队列,可以从队列的两端插入和删除元素。双向队列多了一个端的操作入口,所以在并发时,可以减少一半的竞争。LinkedBlockingDeque比起LinkedBlockingQueue多了操作另一端的方法,所以它的方法offer/put/poll/take是成对的,变成了offerFirst/offerLast/pollFirst/pollLast等。LinkedBlockingDeque可以初始化时指定容量,如果不指定,则为Integer.MAX_VALUE。
LinkedBlockingDeque的并发控制同样使用非公平锁版本的ReentrantLock和两个Condition对象notFull和notEmpty来实现。
一、LinkedBlockingDeque的结构
LinkedBlockingDeque的结构由一个内部类Node表示队列中的节点,Node中有prev,next两个引用分别指向前后节点。LinkedBlockingDeque分别由first、last分别代表队列的首结点和尾节点。还有int型的count和capacity代表队列中的元素数量和队列的容量。相关代码如下:
1 | static final class Node<E> { |
二、LinkedBlockingDeque的主要方法实现
Java[并发]-DelayQueue实现分析
DelayQueue是一个无界阻塞队列,队列中的元素比较特殊,必须是实现了Delayed接口的元素。Delayed接口是一个混合接口,它继承了Comparator接口。它也具有PriorityBlockingQueue的特征,元素中优化级最高的元素是延迟时间最长的元素。队列头的元素是呆在队列时间最长的元素,它只有到时期,才能出队。即getDelay获取到的时间小于等于0时,否则返回null元素。
DelayQueue的并发控制同样使用ReentrantLock和它的Condition对象来实现。因为添加元素不阻塞,所以也只有一个Condition对象来实现等待/通知模式。DelayQueue同样不允许使用null元素。
一、DelayQueue的结构
DelayQueue的结构和PriorityBlockingQueue基本一致,它持有一个PriorityQueue的引用
各种方法实现也委托给了PriorityQueue对象来实现。另外还有一个ReentrantLock和它的Condition对象;队列中的元素是Delayed接口类型的元素。
Delayed接口定义:
1 | public interface Delayed extends Comparable<Delayed> { |
DelayQueue的主要成员变量:
Java[并发]-SynchronousQueue实现分析
SynchronousQueue是阻塞队列的一种,它的特点是每个插入操作必须等待另一个线程的移出操作,反之亦然。同步队列中没有任何元素,队列是没有容量的,不能对队列进行迭代。SynchronousQueue是个空队列,所以队列中不存在null元素。
SynchronousQueue可以使用公平策略,默认为非公平策略,以构造方法传入,公平策略可以保证线程以FIFO的方式进行访问。SynchronousQueue实现了公平/非公平版本,公平版本是以队列FIFO的数据结构实现的,而非公平版本是以栈(LIFO)的数据结构实现的。这两个结构都以内部类的形式出现,它们共同实现了一个abstract类Transfer的transfer方法。
1 | static abstract class Transferer { |
一、非公平版本的Stack实现
1、数据结构 非公平版本的实现是以Stack为数据结构,TransferStack继承Transfer类,实现了它的方法transfer。TransferStack是一个链表结构,它有一个内部类SNode描述了栈中的一个节点,它有一个next引用指向下一个节点。另外SNode还携带了一个match节点,用于和对方线程进行数据交换。
1 | static final class SNode { |