这是我16年设计和开发的项目,并做了总结。当时容器、k8s还未流行,至今看来,异地双活、多活的一些关键技术理念还未过时,业务单元化、业务路由、接管与恢复、基于Mysql的双写和控制缓存、消息、ES等数据同步以达到数据最终一致性的思路仍是最有效的。
以下是原文,有删减:
1.编写目的
双活项目从启动、预研、设计开发测试到上线历时了大约5个月时间,这个历程是我们对业务的一次复盘,也是对分布式系统“异地多活”从思考到实践的过程。因此,对项目过程中的方案、规划和技术等进行总结,沉积这方面的技术和经验是有必要的,也为其它项目解决此类问题提供参考。
2.项目背景和目标
省略
双中心主要提供多活能力,即一个中心崩溃时,关键业务是可以正常提供服务的,例如领礼包、预约礼包核心业务不会有影响。另外快速发现问题和解决问题也是关键的能力。因此双活建设的目标是具备以下三种能力:
- 正常情况下双活能力;
- 灾难情况下容灾能力,即业务接管和恢复能力;
- 快速发现问题和解决问题的能力。
3.项目预研和规划
3.1 现状分析
经过3年多的业务规划和版本迭代,目前已经变得十分复杂,表现为系统模块多,大的方面有核心服务部分,运营管理后台、开放平台、公会、CP服务和外渠服务等。礼包的扩展属性有200多个,对外提供的接口有300多个。核心的场景也比较多,个人、公会、会员、直通车礼包等。
礼包系统是典型的高并发和高吞吐量的系统,接口的性能要求比较高,目前接口日均调用接近1亿+。有20+个业务系统是依赖礼包服务的。另外,基于库存的系统对数据一致性的要求更高。对于这样的系统,怎么把它改造成“异地双活”的系统?面临的困难是比较多的。比如:
- 选择什么方式去实现双活?
- 数据模型和部署方式如何调整?
- 积累了大量的代码如何改造才能减少侵入性?
- 领号性能如何保证?
- 库存如何才能保证一致性?
- 300多个接口怎么保证修改不会出现问题?
- 怎么不会对依赖我们的18个系统不受影响或极少受到影响?
- 故障情况下业务保障如何权衡和取舍?
等等一大堆问题摆在我们面前。
3.2 项目预研
分布式系统的异地多活在业界一直是个难点,在预研过程中也参考大量的方案和思路,基于库存的多活目前基本没有参考的方案。面临的挑战主要有数据一致性问题、数据延迟和数据分散问题。
3.2.1 CAP和BASE
根据分布式系统的CAP理论,Consistency(一致性),Availability(可用性)和Partion Tolerance(分区容错性),三者只能选其二,在分布式系统中P是必选的,建设多活的目标就是需要把A做到极致。那C是不是不要了呢?不是的,这里还有个BASE理论,核心就是怎么处理C的问题,即做不到强一致性,那么就选择弱一致性并最终达到一致性。Base Availability(基本可用)是目标,然后是我们怎么去实现Soft state(柔性事务)和Eventual Consistancy(最终一致性)。双中心的所有方案其实都是根据这个理论去根据业务特点来实现S和E的。
3.2.2 方案预研
1.解决数据一致性问题
解决一致性问题的主要方案就是单元化,把礼包的行为限制在一个单元里面执行,尽可能避免跨机房数据传输。要进行单元化就必须要根据某个数据维度进行数据切分。关于这一点,我们讨论出了两种方案:
- 根据礼包ID进行单元化:把礼包的相关行为如领号、预号和淘号限制在一个机房执行,这样核心业务逻辑改动少,跨机房数据同步比较少;缺点是牺牲就近访问,需要开发路由层,故障情况下,需要进行业务接管和数据恢复等;
- 根据库存进行单元化:即将库存按比例划分,优点是不需要路由层,就近访问。缺点是用户行为产生的数据是需要跨机房同步的,且库存的数据准确性无法保障。同步产生的延迟会导致某些业务规则无法严格约束。
基于阿里的机房间不是专线网络,且方案2对数据的一致性要求很高,最终我们考虑采用了方案1,根据礼包ID进行单元化。
2.解决数据完整性问题
单元化以后,必定会产生数据分散和割裂的问题,比如用户的领礼包数据将会分散在两个集群中,因此,就必须建立数据中心,把数据汇合起来。这里数据中心方案我们采用ElasticSearch作为数据中心的基础 层,并且开发一套组件(ka_dcenter)作为代理接入层。
数据延迟问题是受限于物理网络,硬件等原因,是不可能100%解决的,我们要做的是尽可能避免同步,并在业务允许的情况下,接受一定时间的延迟(1秒内)。同步的组件尽可能采用成熟的方案。因此,我们把业务数据进行了划分,针对不同类别的数据及不同的场景采用不同的策略:
基础类的数据通过mysql主从同步;
业务类的数据按集群分离,各集群有本地业务库,同时也有异地集群从库,这样保障各集群最终能获取到一份全量数据。
数据中心(ES):有些数据需要集中对外提供服务,因此搭建了数据中心;数据中心的同步是通过我们的开发的组件来进行的,方便统一对外提供数据查询服务。
另外,上面采用礼包ID进行单元化以后,如果某个机房故障后,有一半的ID是无法进行操作的,因此,需要提供业务接管和恢复能力。业务接管主要是实现异地的数据能够在本地进行操作,对此,主要方案是进行“写时复制”策略,即需要的数据将从异地业务数据从库读并复制到本地库进行写,在此过程中,记录接管流水日志,以便数据恢复时使用。接管只是针对核心的几个业务场景提供的,并且是有一些体验损失的服务。恢复的逻辑主要是把接管产生的异地数据恢复到它本来所属的集群中去,以保持集群数据的完整和一致性。
3.业务保障的权衡和取舍
双活的目的是为了解决故障情况下带来的业务影响,具体出现故障后哪些业务可以不受影响,哪些业务提供有损服务?根据礼包业务的特点,为了保障故障情况下核心业务的体验,我们确定了业务维度的目标:
- 所有业务读场景提供正常服务,如:礼包业务对外提供的各类查询接口;
- 非库存强一致性写场景提供正常服务,如:预号、淘号等操作;
- 强库存一致性写场景提供“延迟服务”:如:领礼包操作,当其中一机房出现故障,另外一个机房接管,针对用户领礼包操作,系统采用延迟发放策略,即:系统记录用户发放请求,提示用户礼包正在发放中,待机房恢复后,由数据所属机房完成整个发放操作。
4.总体方案
最终通过上面的分析和研究后,我们确定的总体结构图如下:
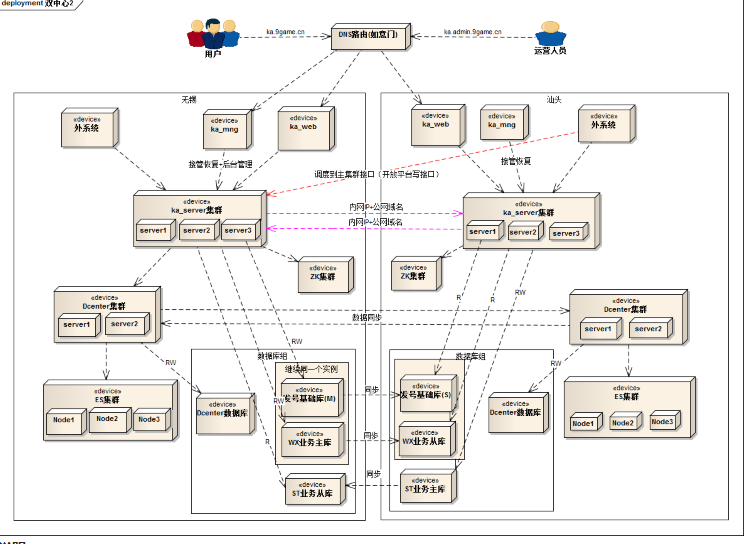
说明:
- 路由功能由ka_server承载,根据路由规则把请求分派到对应的集群处理;
- zookeeper集群用于管理集群的状态变化;
- DCenter集群作为ES数据中心的代理接入组件;
- 在两个机房中分别部署独立的ES数据集群;
- 数据库划分为基础库和业务库:基础库以无锡作为主库,单向同步到汕头;业务库两边分别有主库和异地从库,集群间单向同步的方式。
3.3 项目规划
在大体方案确定以后,就进入实施阶段了。根据方案,制定了总体的计划如下图:

具体实施的内容如下:
1.数据模型初步调整和数据中心建设(2016.10.15-2016.12.15)
这个阶段主要进行一些外围的基础工作,不进行业务改造。数据模型调整,把目前的数据库划分为基础库和业务库两类,基础库主要是礼包的基础数据,主要面向的是运营人员;而业务库是礼包的行为数据,主要是用户产生的。在ES基础上搭建数据中心代理接入组件,主要是索引管理、搜索、数据同步,一致性校准等功能。另外,对定时任务也进行了兼容改造。
2.业务改造和容灾能力建设 (2016.12.15-2017.3.18)
这个阶段是主要实现双活的阶段,包括路由组件、后台管理、接口兼容等。容灾能力建设方面主要是集群状态调度功能、业务接管和恢复功能的实现。
4.设计和实现
4.1ID生成问题
一般情况下,ID是无业务含义的,但在多集群部署时,需要赋于ID集群的含义,用于识别该数据所属集群。发号目前使用的是long型的ID,对应mysql是bigint类型,长度为19。因此,我们改造了原来的ID生成规则,由原来的10位时间戳+3位appid+6位自增数规则改为:10位时间戳+1位集群ID+3位appid+5位自增数,并且第1位+1,目的是和历史记录的ID区分。
4.2 路由规则
路由主要由框架自带的拦截器实现,路由目前路由规则主要是根据接口的功能来划分需要执行的策略,目前主要有几种策略:
根据请求参数中的ID所属集群进行路由;
故障情况下接管的路由;
只路由到主集群;
缺省情况下的路由。
路由的总体设计图如下:
 |
|
|---|---|
在进入到controller之前实现接入层,接入层解析请求参数并判断该请求是否有本机房处理:
- 由本机房处理将进入正常的Controller层进行处理;
- 由异地机房处理可通过接口透传的访问访问异地机房(依赖服务中心调度)。
4.3 业务改造
业务改造的关键在于数据库模型发生变化以后,我们的接口逻辑怎么适配新的模型的问题。也就是要解决数据的完整性和一致性问题。在业务改造过程中,我们是通过以下方案来实现的:
在代码结构上引入新的逻辑代理层,涉及本异地数据判断、合并的实现都在代理层实现;
涉及业务库查询需要排序、分页类的接口都从ES数据中心查询;
双中心之间数据传输使用JWS的RPC来实现;
对于严格需要保障一致性的跨机房数据传输,使用记录请求流水日志和重试机制来保障;
4.4 定时任务改造
发号的定时任务原来实现的手段差异较大,对此我们做了改造,在基于Quartz组件的基础上,进行了封装和提供统一的接口,简化了任务的实现复杂度,针对双中心也做了适配并提供了简单的管理后台 。
定时任务的模型如下图:

定时任务主要的设计思路如下:
- 封装Quartz组件,提供一致的实现接口;
- 针对任务的执行的进程和线程,分为4种方式;
- 各中心JVM进程读取本中心的define.conf配置和hostname对比,决定中心里面哪台机器执行任务;
- 从本中心的基础库读取定时任务配置并初始化定时任务;
- 根据定时任务的数据来源决定是读取主库还是ES数据中心;
- 涉及操作异地中心的数据通过RPC接口来实现。
4.5 接管和恢复
接管的目标是保证异地机房故障时,核心业务的基本可用。因此,目前接管的只是个人的礼包操作行为,领号、预号和淘号操作。因为涉及到库存的问题,对于领号采用用“延迟发放”的策略,即用户在故障时,领取操作流程是顺畅的,但真正的兑换码不在接管时发放,在故障机房恢复时才真正发放。预号和淘号因为不是基于库存的操作,接管时和正常时的服务对用户来说是一致的,无感知的体验。
接管和恢复涉及到了集群的状态变化问题,因此,我们引入了zookeeper管理集群的状态。接管集群从zookeeper获取到接管状态后,该集群进入接管另一个集群业务数据的状态,根据路由的判定后,进入接管逻辑层,根据具体的业务场景进行接管,并写接管流水日志。
接管模块的总体流程图如下(汕头处于接管状态):

- 首先由发号后台向zookeeper发送接管状态;
- 集群状态管理类监听到zookeeper节点状态变化后,更新本地内存中的集群状态;
- 具体需要接管的业务逻辑判断当前集群是接管状态后,进入接管的业务逻辑;
- 接管过程中,会根据业务逻辑,把异地从库的数据读到本地处理,同时写接管流水日志。
恢复时,需要恢复的集群的恢复框架从异地业务库读取接管日志表,并执行恢复操作,即把接管产生的数据恢复到本地集群中。
恢复的总体流程如下:

- 这里假设无锡集群处于恢复状态,汕头集群通过管理后台把状态恢复为正常,不再接管无锡数据;
- 恢复模块开始读取异地从库中的接管流水记录;
- 根据接管流水记录开始“重放”对应的接管业务,把异地从库的数据恢复到主库。
- 这时要注意数据时序问题和ES数据中心数据跟数据库数据一致问题。
- 恢复完成后,通过RPC调用汕头集群接口删除接管日志。
4.6 数据中心代理接入组件
发号原来使用的全文检索用的组件是Sphinx,Sphinx使用简单,但有无法分布式部署和不好维护的缺点。双中心我们准备搭建数据中心,采用了ES作为基础层,为了更好地使用ES,我们开发了ES的代理接入组件ka_dcenter,它初期的主要功能是索引管理、提供给业务使用的一套封装好的API、集群数据同步和数据一致校准等。索引管理主要通过配置的方式,把数据库数据与ES关联起来。API主要ES索引创建、更新、删除和搜索接口的封装。集群数据同步是通过日志流水表来实现的,数据一致性校准是通过定时任务进行增量与数据库数据进行同步对比来实现。
数据中心的总体结构图如下:

无锡、汕头机房各自建立数据中心,为本机房提供服务;
两个数据中心绝大部分数据是等价的,存在部分延迟的不一致数据;
“数据中心服务”组件为独立部署应用,对外提供数据的索引、检索服务。内部负责数据一致性维护,数据安全策略,监控、日志等。
4.7 缓存同步策略
根据双中心的整体架构,两个集群的缓存是独立存在的。对于业务数据的操作,各自更新本集群的缓存是没有问题的。但针对发号基础数据的操作,如礼包数据变更,只会刷新一边集群的缓存,另一边集群是不知道的。开始我们准备通过飞鸽通知的方式,但会存在时序问题。在主集群更新了数据,通过主从同步到另一个集群时,如果消费消息的速度比同步快,那么另一边集群其实是刷新到了旧的数据。第二个方案是通过记录缓存变更的key到数据库,利用主从同步的数据库记录的顺序来保证时序。然后通过主集群RPC调用异地集群来更新缓存,这样就保证异地集群刷新缓存后的数据是新的数据。
实现流程如下图所示:

- 当无锡集群的礼包信息发生变化时,把变化的缓存key记录到数据库缓存流水日志表中;
- 通过数据库的主从同步,把缓存流水日志表同步到汕头;
- 无锡集群通过定时任务,定时通过RPC调用汕头缓存刷新接口;
- 汕头缓存刷新接口读取缓存流水日志表中的缓存key,刷新本集群的缓存;
- 无锡根据RPC接口返回值,如果成功则删除缓存流水日志表记录。
5.部署和演练
5.1 部署
部署分为三个阶段进行:
- 第一阶段:定时任务改造、ES、ES的代理接入组件ka_dcenter部署,数据库方面包括基础库划分,分库表合并等。第一阶段部署后,基本的外围基础功能已经搭建,并且全文检索组件从sphinx切换为ES,运行良好。
- 第二阶段:这个阶段是比较部署是比较复杂的,涉及到整个发号系统的改动,因此对部署方案进行了多次评审和确认,部署过程也划分为几个阶段:
1)首先是数据库的调整,这个阶段主要由DBA通过UCMHA的切换也进行,基本对线上的业务没有影响;
2)然后进行ES数据中心数据初始化,也花了较长时间;接着发布发号接口服务 ,路由功能和整个业务改造功能上线。
3)最后是附属的组件页面和后台管理发布。整个过程不是很顺利,业务接口切换到ES数据中心 时,ES出现接口响应慢的问题,不得不中断部署,解决了这个问题后再继续。
第三阶段:这个阶段主要是接管和恢复功能发布,这个过程比较简单。很快就发布和验证成功。
在整个部署过程中,我们都采用灰度部署的方式,即不进行全量发布,只是发布一台机器,验证后再继续发布。后来证明这是有效的,在灰度发布过程中发现了一些问题并及时修复,避免了对业务造成较大的影响。
5.2 灰度测试
在每个发布阶段,我们都进行了灰度测试,即通过配置的方式,只针对某些游戏和礼包做测试,且这些礼包是用户不可见的。除非通过配置手段,我们还通过名字服务中心进行灰度引流,即只引流少部分请求。通过这两种种手段,我们验证了业务逻辑和数据的正确性。然后再逐步把数据向用户开放,再针对用户的产生数据进行验证,以保证功能没有问题。
5.3 演练
双中心项目发布后,为了检验在故障情况下,核心的业务场景是否能够正常服务。并且在故障时,具体的应对措施是否有效,因此,进行演练是很有必要的。我们根据机房的环境和部署情况,和运维的同学梳理出了故障的三种情况并制定了对应的措施:
场景一:VPN故障(汕头无锡内网访问故障,外网正常)
场景二:汕头机房故障(不能对外提供服务)
场景三:汕头核心故障(不能对外提供服务,且内网VPN故障)
从我们双中心的部署结构上来说,场景一和二基本是没有影响的。重点是场景三,需要进行业务接管和恢复操作。演练耗时2小时,成功完成了演练。但随着后面版本迭代和业务逻辑变更,演练应该成为一个长期的机制,通过工程化把它固定下来,成为双活集群的一项功能。
6.日志和监控
日志和监控对系统来说非常重要,日志用于回溯和排查,监控预警可以提高发现问题的能力,两者是相辅相成的关系,完善的日志和监控体系也是我们当初双中心制定三项能力中一项。
6.1 日志
目前发号的日志主要以JWS自带框架为主,并增加了核心的业务日志如领号,api日志,用于追踪接口的请求响应,定时任务日志,外部调用日志,引入立体监控日志,并且对双中心的各项功能也增加了日志。
另外,我们还把日志输出到日志分析平台,以便更好的检索和排查 。
6.2 监控
在监控方面,由自实现的监控和立体监控的棱镜监控相互补充。发号自己实现的监控主要分为两大类,业务监控和系统监控,通知机制主要是通过钉钉、邮件和短信。业务监控力求覆盖核心的业务情景,针对错误、发号数据异常,外系统数据异常等场景采用即时触发的方式预警,而对影响不大的监控采取定时触发的方式进行。