事务的隔离性由锁来实现,事务的原子性、一致性、持久性通过数据库的redo log和undo log来完成。Redo log称为重做日志 ,用来保证事务的原子性和持久性,undo log用来保证事务的一致性。redo和undo都可以认为是一种恢复操作,redo 恢复提交事务修改页的操作,而undo回滚行记录到特定的版本;redo通常是物理日志 ,记录的是页的物理修改操作,undo是逻辑日志 ,根据每行进行记录。
一、Redo的基本概念
重做日志由两个部分组成:一是内存中的重做日志缓冲(redo log buffer),二是重做日志文件(redo log file)。
InnoDB引擎通过Force Log At Commit的机制实现事务的持久性,即当事务提交时,必须将该事务的所有日志写到重做日志文件进行持久化,这里的重做日志指redo log和undo log。redo日志基本按顺序写,而undo日志则需要随机写。
为了确保每次日志都写入重做日志,在每次将重做缓冲写入重做日志后,都需要调用一次fsync操作,fsync的效率决定于磁盘的性能,因此碰盘的性能决定事务提交的性能,也就是数据库的性能。
参数innodb_flush_log_at_trx_commit用来控制重做日志刷到磁盘的策略,默认值为1,表示事务事务提交时必须进行一次fsync操作。0代表事务提交时不会写入重做日志操作,这个操作只在master thread完成,而master thread每1秒会进行一次fsync操作。2表示事务提交时将重做日志写入重做日志文件,但只写入文件缓冲,不会进行fsync操作。这种情况下,mysql宕机而操作系统不宕机时,不会丢失事务。
关于innodb_flush_log_at_trx_commit参数设置对数据库性能影响的例子:
1 | CREATE TABLE test_flushlog( |
在innodb_flush_log_at_trx_commit=1时,耗时1分13秒;
SET GLOBAL innodb_flush_log_at_trx_commit=0;
在innodb_flush_log_at_trx_commit=0时,耗时1.271秒;
SET GLOBAL innodb_flush_log_at_trx_commit=2;
在innodb_flush_log_at_trx_commit=2时,耗时8.625秒;
二、Log block
重做日志都是以512字节进行存储,这意味着重做日志文件、重做日志缓冲都是以块(block)的方式进行保存的,称为重做日志块(redo log block)。由于重做日志块512个字节大小与磁盘的扇区是一样的,因为写入是原子性的,不需要doublewrite技术。
重做日志块由重做日志头(redo log header)、重做日志尾(redo log tailer)和重做日志的内容组成。重做日志头占用12个字节,尾占用8个字节。因此每个重做日志块可以存储492个字节。
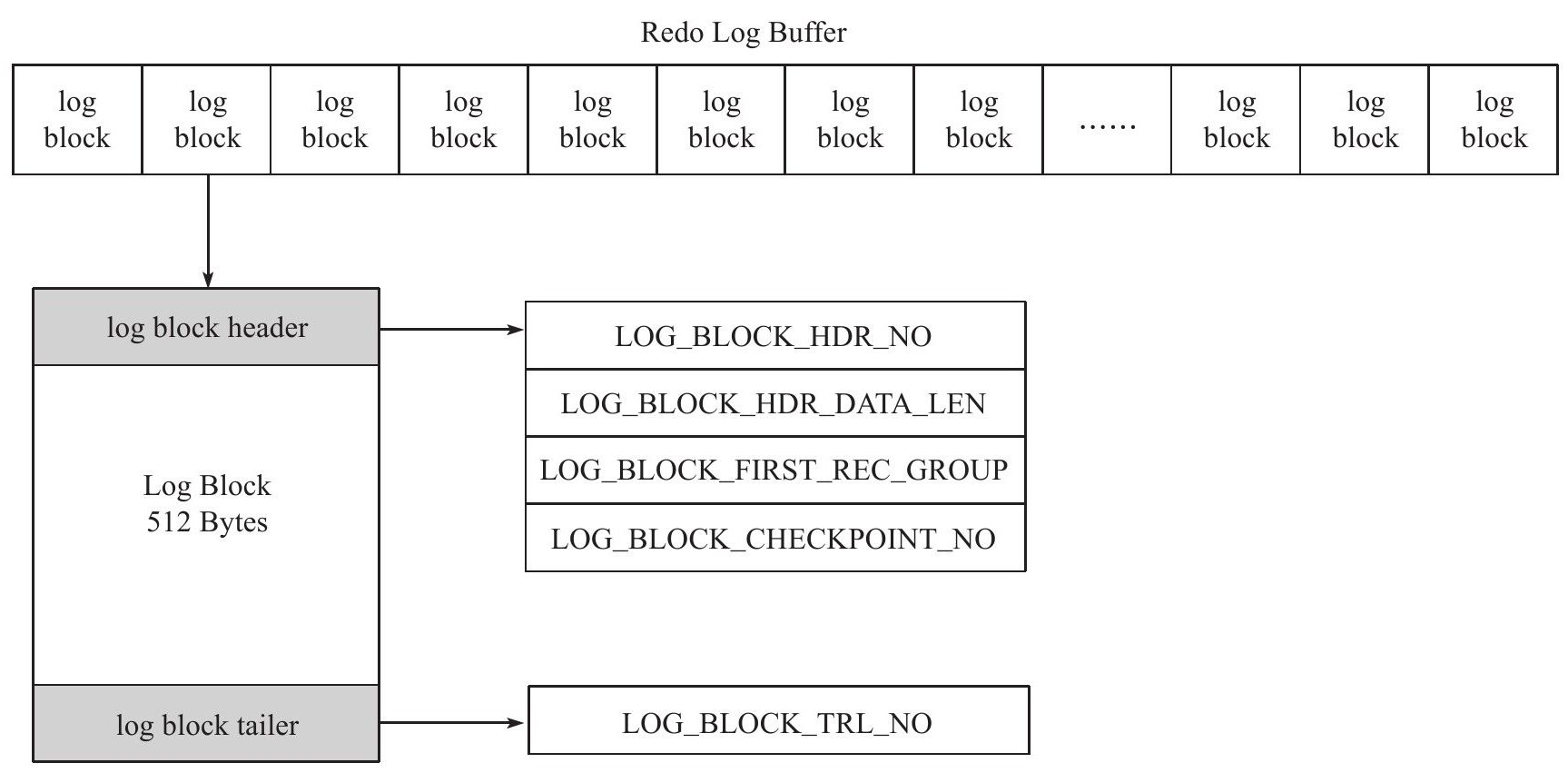
重做日志头的组成部分如下:
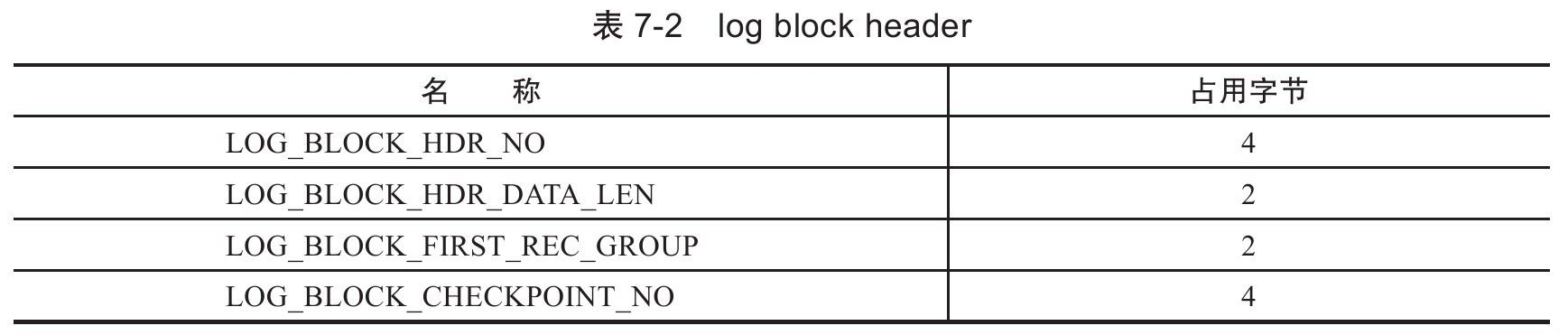
Log buffer类似由log block组成的数组,而LOG_BLOCK_HDR_NO用来标记数组中的位置;
LOG_BLOCK_HDR_DATA_LEN代表重做日志的大小,当写满时,值为0x200,即512字节;
LOG_BLOCK_FIRST_REC_GROUP代表log block中第一个日志的偏移量,如果值大小与LOG_BLOCK_HDR_DATA_LEN相同,代表log block中不包含新的日志。如事务T1的日志大小为762字节,而事务T2大小为100字节,则在Log buffer中的情况如下图:
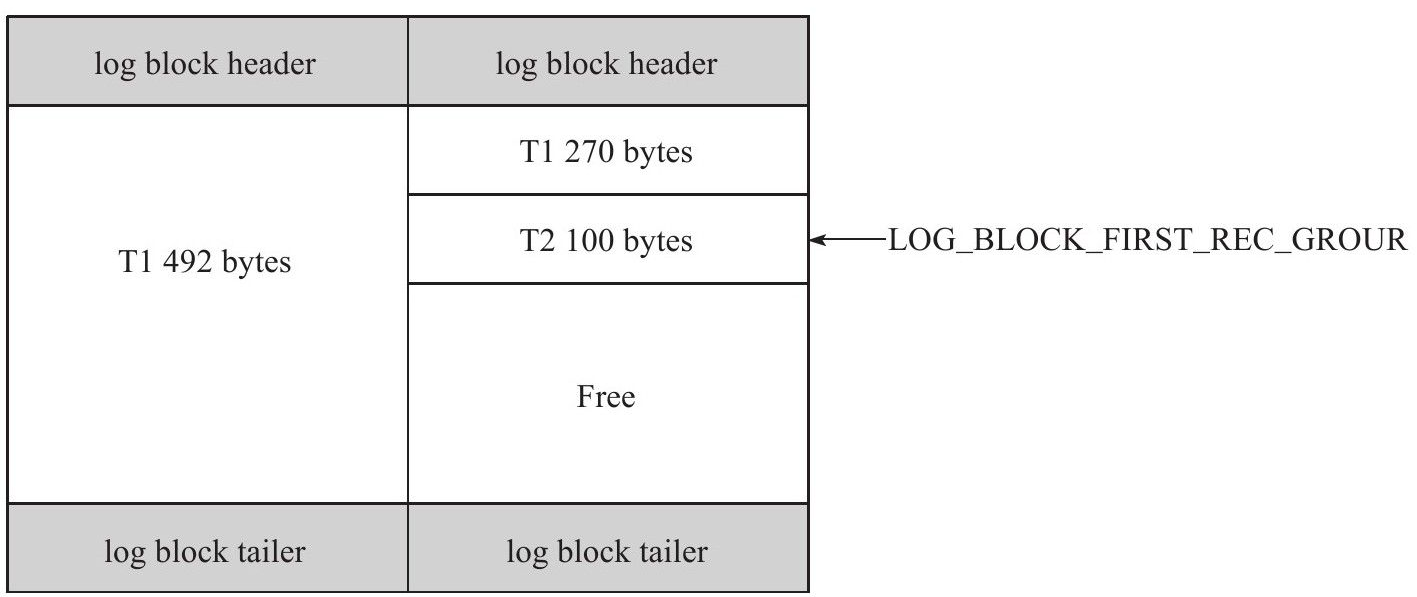
右侧的log block的LOG_BLOCK_FIRST_REC_GROUP为270+12=282;
LOG_BLOCK_CHECKPOINT_NO占用4个字节,表示该log block最后被写入时检查点的第4字节的值;
Log block tailer由一个部分组成,且其值和LOG_BLOCK_HDR_NO相同。

三、Log group
Log group 为重做日志组,其中有多个重做日志文件。InnoDB实际上只有一个日志组。日志组是一个逻辑上的概念,由多个重做日志文件组成。
重做日志文件保存的就是log buffer中的log block,log buffer根据一定的规则将内存中的log block刷到磁盘。
• 事务提交时;
• 当log buffer有一半的内存空间已经被使用时;
• Log checkpoint时。
对于log group的第一个 redo log file,其前2KB的部分保存4个512字节大小的的块,其中的内容如下表:

以上信息只有第一个redo log file中保存,其它的redo log file仅保留空间,不保留信息。因此,对redo log file的写入不是顺序的。
四、重做日志的格式
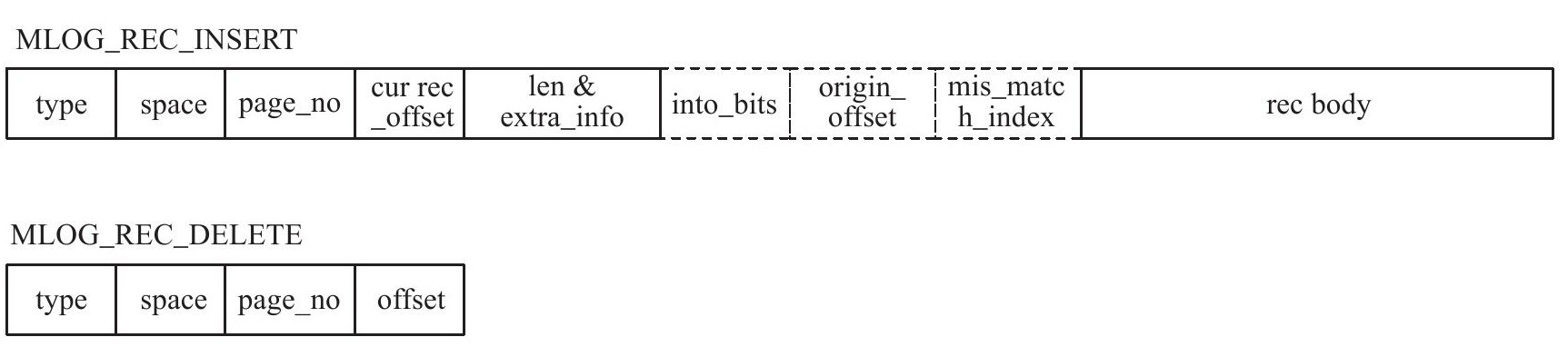
因为innodb引擎存储是基于页的,因此重做日志也是基于页的,虽然重做日志有不同的格式,但有着通用的头部:

通用的头部格式由以下部分组成:
• Redo_log_type:重做日志的类型
• space:表空间的ID
• Page_no:页的偏移量
之后的redo log body部分,根据redo log类型的不同,存储不同的内容。
对应页上记录的插入和删除,重做日志分别对应下表的格式:
五、LSN
LSN是log sequence number的缩写,代表日志序列号,占用8个字节,并单调递增,LSN代表的含义有:
• 重做日志写入的总量
• checkpoint的位置
• 页的版本
LSN表示事务写入日志的总量,单位为字节,比如当前LSN为1000,事务T1写入了100个字节,则LSN变为1100。LSN不仅记录在重做日志中,而且记录在每个页中,在每个页的头部,有一个值FIL_PAGE_LSN记录了该页的LSN。在页中,LSN代表刷新时LSN的大小。因为重做日志记录是每个页的日志,因此页中的LSN用来判断页是否需要进行恢复操作,例如页中的LSN为1000,而数据库启动时,检测到重做日志中的LSN为1300,并且事务已经提交,那么就需要进行恢复操作。
通过命令SHOW ENGINE INNODB STATUS可以查看LSN的情况。
LOG
Log sequence number 107369863
Log flushed up to 107369863
Pages flushed up to 107369863
Last checkpoint at 107369863
0 pending log writes, 0 pending chkp writes
8 log i/o’s done, 0.00 log i/o’s/second
Log sequence number代表当前的LSN值,Log flushed up to代表刷新到重做日志文件的LSN,Last checkpoint at代表刷新到磁盘的值。这三个值在生产环境中可能是不同的,因为一个事务从日志缓冲刷新到重做日志文件并不只是在事务提交时发生,每秒都有从日志缓冲刷到磁盘日志文件的操作。
六、恢复
由于checkpoint代表已经刷到磁盘的LSN,因此恢复过程只需要恢复checkpoint开始的日志部分,当数据库在checkpoint=10000时发生宕机,恢复操作仅恢复10000~13000之间的日志。
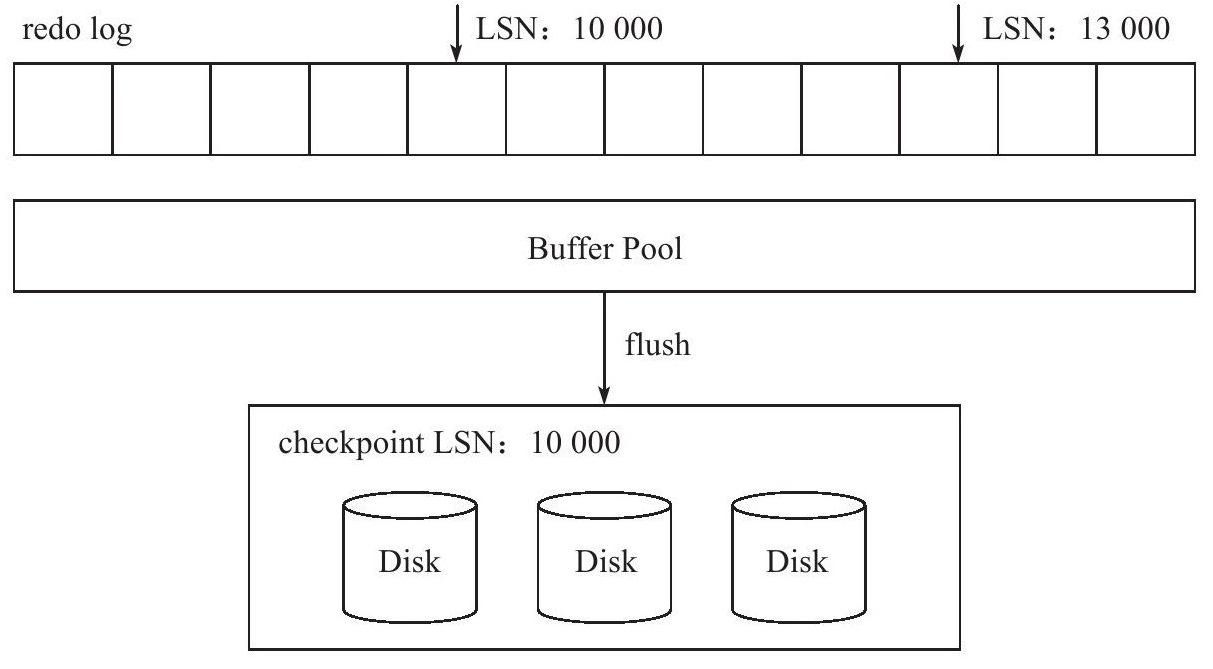
innodb引擎存储的重做日志是物理日志,因此恢复比二进制日志快。例如对insert操作,记录的是每个页的变化,对于以下表:
CREATE TALBE t(a INT,b INT,PRIMARY KEY(a),KEY(b));
若执行INSERT INTO t SELECT 1,2;
由于需要对聚集索引和辅助索引页进行操作,其记录的重做日志大约为:
Page(2,3),offset 32,value 1,2 #聚集索引
Page(2,4),offset 64,value 2 #辅助索引
参考《MySQL技术内幕 -InnoDB存储引擎》整理,如侵权请联系vinin@163.com。