innodb索引的类型有:
• B+树索引
• 全文索引
• 哈希索引
B+树索引并不能找到给定键值的具体行,而是找到行所在的页。然后数据库把页读到内存中再查找。
每页的Page Directory中的槽是按照主键的顺序存放的,对某一条具体记录的查询是通过对Page Directory进行二分查找得到的。
一、B+树
B+树由B树和索引顺序访问方法(ISAM)演化而来。
B+树是为磁盘或其他直接存储辅助设备设计的一种平衡查找树,在B+树中,所有的记录节点都按键值的大小顺序放在同一层的叶子节点上,由各叶子节点指针进行连接。下面的B+树高度为2,每页存放4条记录,扇出(fan out)为5。
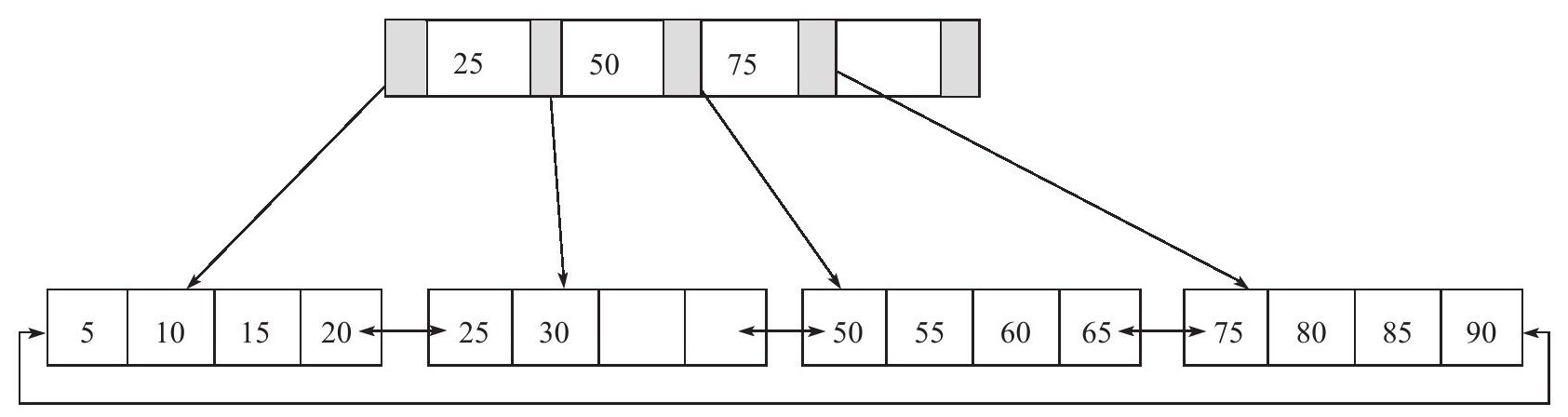
二、B+树索引
B+树索引的本质是B+树在数据库中的实现。B+树在数据库中特点是高扇出性,即一般B+树高度一般2-4层,查找某键值时,一般进行2-4次IO,意味着查询耗时在0.02-0.04秒之间。
B+树索引可以分为聚集索引(Clustered Index)和辅助索引(Secondary Index)。两者的区别在于叶子节点是否存一整行信息。
1、聚集索引
聚集索引就是按照每张表的主键构造一棵B+树,同时叶子节点存放的即为整张表的行记录数据。也将聚集索引的叶子节点称为数据页。同B+树结构一样,每个数据页都通过双向链表来进行链接。
由于实际页只能按照一棵B+树来排序,因此每个表只能有一个聚集索引。由于定义了数据的逻辑顺序,聚集索引能快速地访问针对范围值的查询。
存储的结构例子:
建表,一页只存两条记录:
CREATE TABLE t3(
a INT NOT NULL,
b VARCHAR(8000),
PRIMARY KEY(a)
) ENGINE=INNODB;
INSERT INTO t3 SELECT 1,REPEAT(‘a’,7000);
INSERT INTO t3 SELECT 2,REPEAT(‘a’,7000);
INSERT INTO t3 SELECT 3,REPEAT(‘a’,7000);
INSERT INTO t3 SELECT 4,REPEAT(‘a’,7000);
使用py_page_info工具查看:
D:\Python27\python.exe E:/gitrepos/pyscripts/innodb/py_innodb_page_info.py -v D:\wamp\bin\mysql\mysql5.6.17\data\test\t3.ibd
page offset 00000000, page type
page offset 00000001, page type
page offset 00000002, page type
page offset 00000003, page type
page offset 00000004, page type
page offset 00000005, page type
page offset 00000006, page type
page offset 00000000, page type
Total number of page: 8:
Freshly Allocated Page: 1
Insert Buffer Bitmap: 1
File Space Header: 1
B-tree Node: 4
File Segment inode: 1
Page level为0000的为数据页,而0001的是B+树的根,因为当前B+树的高度为2。用 UE来观察索引的根页中存放的数据,因为pageoffset为3,即前面有16K3=49152个字节,即在UE里面的位置为0000C00=1216的3次方。

…
页尾位置:

通过页尾的Page Directory来分析此页,从00 63可知该页中行开始的位置,接着通过Record Header来分析,0xc063开始的值为69 6E 66 69 6D 75 6D 00 ,就代表infimum为行记录,之前的5个字节01 00 02 00 1B即为RecordHeader,分析到第4位到第8位的值1代表该行记录只有一条记录(InnoDB的PageDirectory是稀疏的),即infimum记录本身。通过RecordHeader最后两个字节00 1B来判断下一条记录的位置为:c063+1b=c07e,读取键值可得到:80 00 00 01(表定义INT无符号,因此二进制是0x80 00 00 01,而不是0x0001),80 00 00 01的后面的00 00 00 04值代表指向数据页的页号,同样的方式只以找到80 00 00 02和80 00 00 04这两个键值和它指向的页号。

聚集索引的好处是,对主键的排序查找和范围查找速度非常快,叶子节点的数据就是用户需要的数据;
针对排序查找,根据双向链表的特征,可以快速定位所在的数据页,并取出数据;
针对范围查询,可以通过叶子节点的上层中间节点找到页的范围,之后直接读取数据页即可。
2、辅助索引
辅助索引的叶子节点没有包含所有的行记录数据,叶子节点除了包含键值外,每个叶子节点的索引行中还包含一个书签(bookmark),用来记录与索引相对应的行数据,即是聚集索引的键。
辅助索引与聚集索引的关系图:

当通过辅助索引来查找数据时,InnoDB引擎会遍历辅助索引并通过叶子级别的指针来获得指向主键索引的主键,然后再通过主键索引来找到一个完整的行记录。
在t3表中加一列数据和建立辅助索引来分析辅助索引的存储结构:
ALTER TABLE t3 ADD c INT NOT NULL;
UPDATE t3 SET c=0-a;
ALTER TABLE t3 ADD KEY idx_c(c);
用py_page_info.py工具查看表空间存储:
D:\Python27\python.exe E:/gitrepos/pyscripts/innodb/py_innodb_page_info.py -v D:\wamp\bin\mysql\mysql5.6.17\data\test\t3.ibd
page offset 00000000, page type
page offset 00000001, page type
page offset 00000002, page type
page offset 00000003, page type
page offset 00000004, page type
page offset 00000005, page type
page offset 00000006, page type
page offset 00000007, page type
page offset 00000000, page type
page offset 00000000, page type
Total number of page: 10:
Freshly Allocated Page: 2
Insert Buffer Bitmap: 1
File Space Header: 1
B-tree Node: 5
File Segment inode: 1
分析page offset为4的页,即为非聚集索引所在的页,通过UE打开到16K4=161024*4=65536=16的四次方=00010000;

页尾的 Page directory:

因为只有4行且C列只有4个字节,可以在一个非聚集索引页中完成。
整理分析可得如下图的关系:

可以看到辅助索引的叶子节点中包含了列C的值和主键的值,-1以7f ff ff ff的方式存储,7(0111)最高位为0,代表负值,实际值取反后加1,即为-1。
参考《MySQL技术内幕 -InnoDB存储引擎》整理,如侵权请联系vinin@163.com。